文章详情
国外花了40年才明白的I/I诊断方法:不是算总量,而是分区测流量
2026-06-10
一、I/I诊断方法的四重困境
困境一:水量平衡法"参数悬空"
折污系数:不同城市、不同用水类型差异显著,但多数项目直接套用全国平均值
污水收集率:老城区与新城区、中心城与远郊区的管网完善程度差异巨大,却常常被统一赋值
产污人口:大流动背景下,常住人口与实际产污人口往往严重偏离
一个参数可能存在10%左右误差,经过传递放大,可能导致I/I估算结果偏差30%-40%以上,结果就丧失了参考价值。
困境二:入渗公式"好看不好用"
困境三:入渗与入流"混在一起分不清"
入渗的治理手段是管道修复(内衬、密封、局部修复)
入流的治理手段是错接改造(雨污分流、封堵非法接入)
困境四:控制措施"简单粗暴"
二、国际经验:从总量估算到分区监测的40年演进
第一阶段:总量估算期(1970s-1990s)
第二阶段:RTK方法期(1990s-2010s)
R(Rainfall Volume Fraction):降雨转化为I/I的比例
T(Time to Peak):从降雨开始到I/I峰值出现的时间
K(Recession Ratio):I/I消退速度与峰值时间的比值
第三阶段:分区监测期(2010s至今)
美国Pinole市(2014):将管网划分为多个子流域,在每个子流域出口安装流量计,通过I/I归一化指标(gpd/IDM、gpd/acre、I/I/ADWF ratio)对子流域进行排序,识别I/I热点区域。在0.85英寸降雨下,不同子流域的峰值系数从4.9到67.5不等,差距超过13倍——这说明I/I在管网中的分布极不均匀,总量估算毫无意义。
德国巴登-符腾堡州:基于系统的流量监测数据,采用水量平衡和化学质量平衡相结合的方法,精确区分污水、入渗水和入流水的比例。研究表明,新建管网系统的RDII比例可控制在15%,而老旧系统平均达35%。
挪威特隆赫姆市:采用"分区流量监测→示踪剂定位→分布式温度传感→CCTV/烟雾测试"的四级递进方法,从宏观量化逐步走向微观定位。

三、第一性原理:为什么流量分区监测是I/I诊断的最优解
| 分区流量监测法 | 直接测量分区出口流量,数据实测 | 高,并且就是当前的实际情况 | 高 |
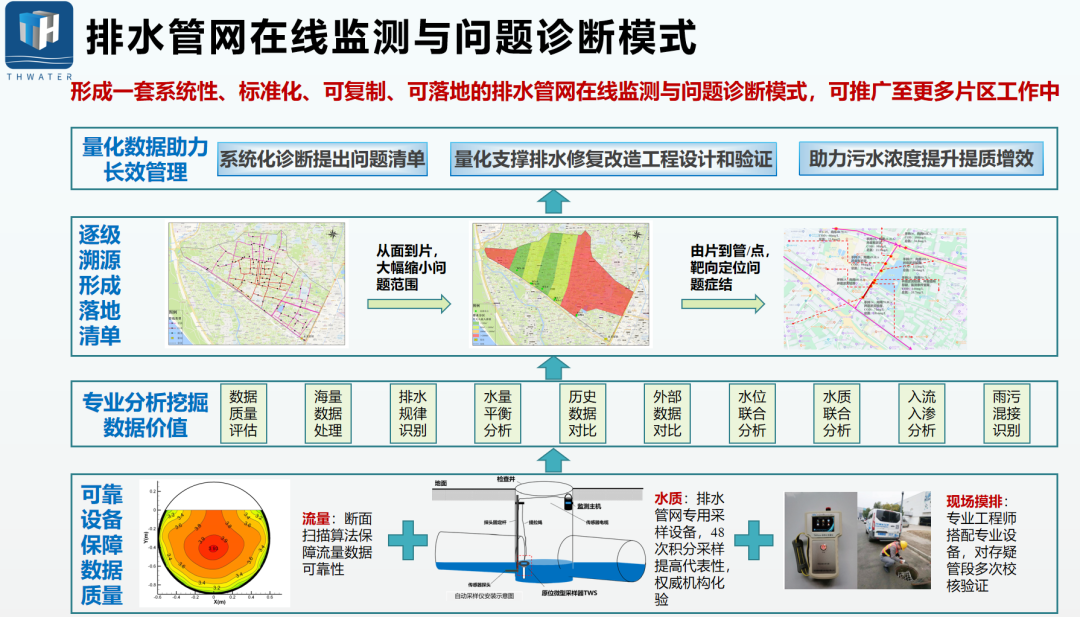
四、清环智慧的"分区多点位连续流量监测"方法论
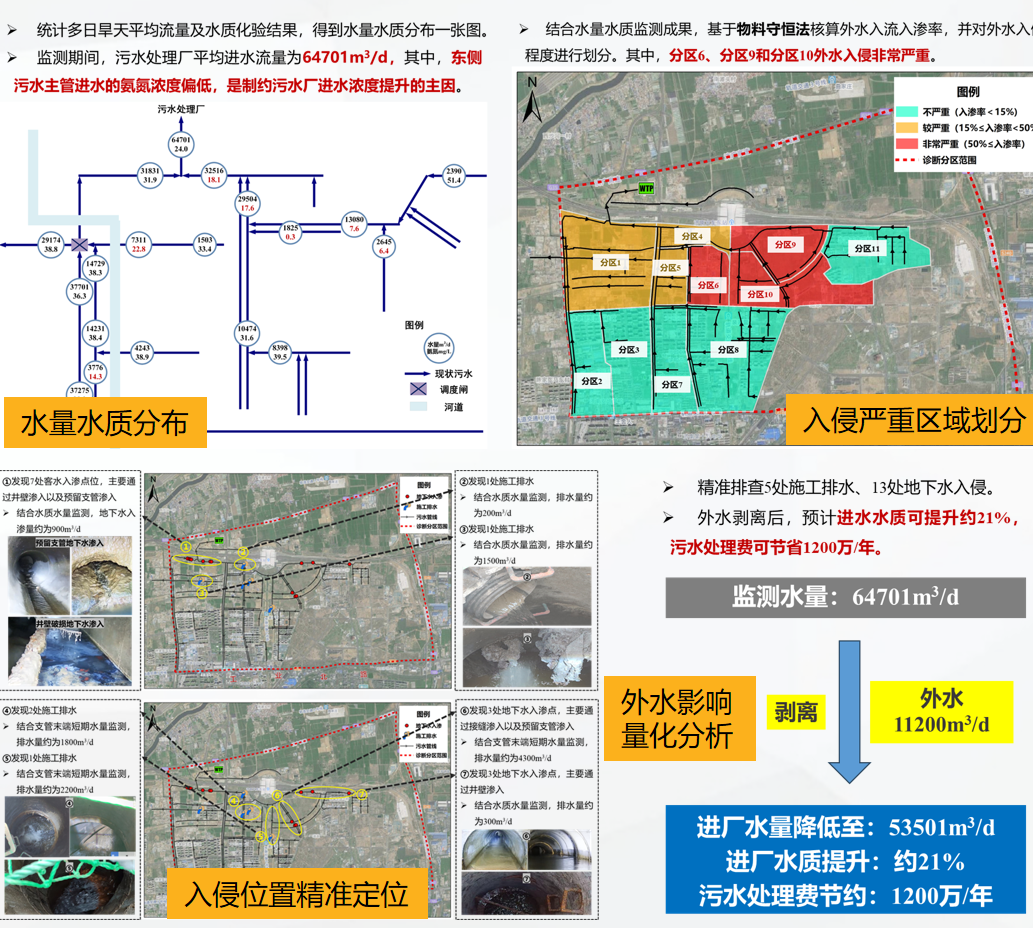
第一层次:科学分区,分片管理
第二层次:多点位连续监测,数据驱动
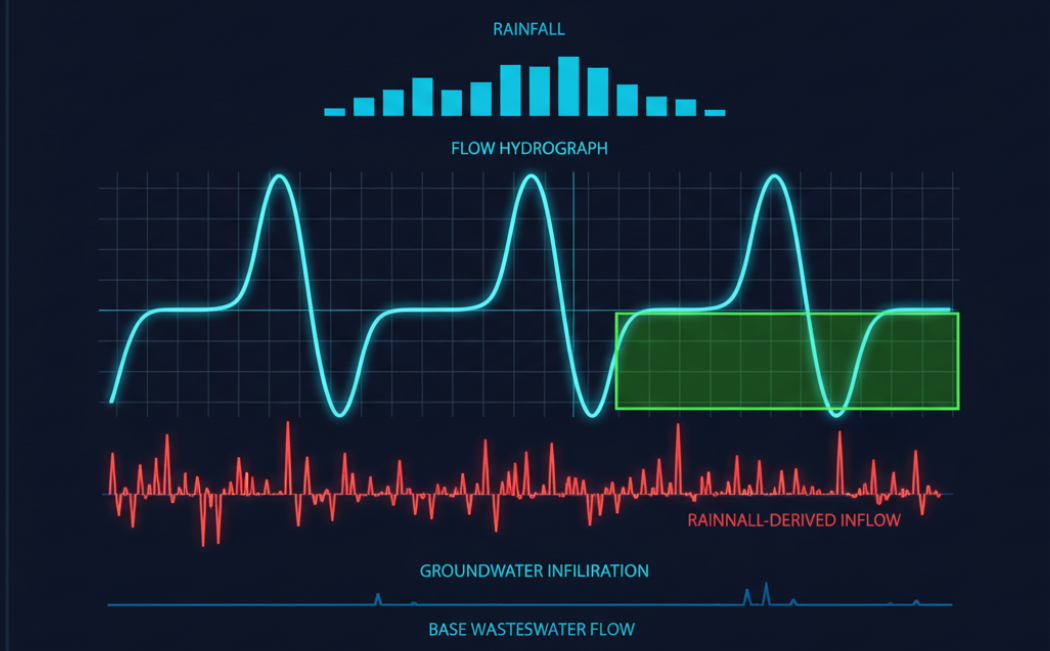
I/I总量:分区出口实测流量 - 理论产污量 = I/I量(m³/d精度)
I/I类型:通过降雨响应特征区分入流(尖峰响应)和入渗(基线抬升)
I/I空间分布:对比不同分区的I/I率,识别热点区域
第三层次:三级递进,从诊断到定位
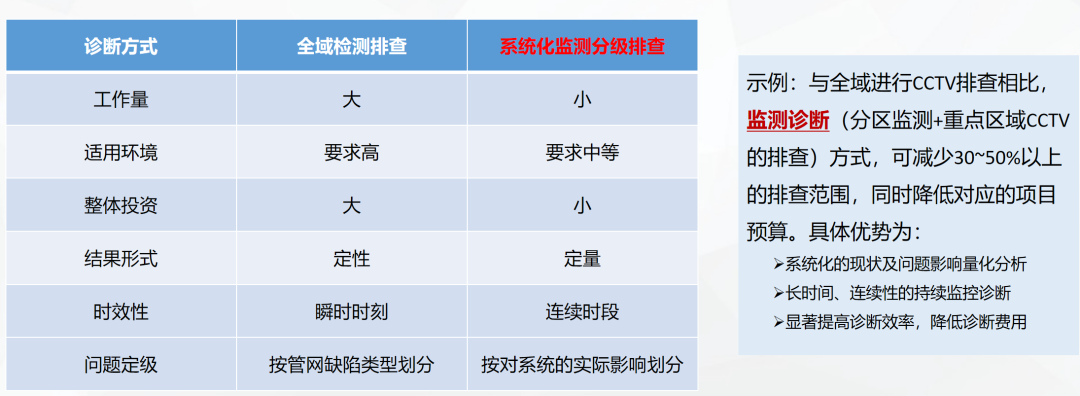
五、方法对比:为什么分区流量监测优于传统方法
| 分区流量监测法 | |||
|---|---|---|---|
| 核心变量 | 分区出口流量(实测) | ||
| I/I分离能力 | 入渗/入流可定量分离 | ||
| 空间分辨率 | 分区级别精细分布 | ||
| 数据要求 | 连续流量监测数据 | ||
| 动态追踪 | 连续动态变化 | ||
| 验证能力 | 整治前后数据对比直接验证 | ||
| 工程指导价值 | 高(告诉"哪有问题、什么问题、多严重") |
六、写在最后:从"算一个数"到"解决一个问题"
分享